
🤔 What is the Most Downloaded AI Model? 📥🤖✨
Would you like to be featured in our newsletter🔥 and get noticed, QUICKLY 🚀? Simply reply to this email or send an email to editor@aibuzz.news, and we can take it from there.



Tabular data models demonstrate an unsung portion of AI model universe by managing complex data
Part 2 of the AI Model Series, by Liftr Insights
There are models downloaded 8x more, on average, than the traditional types of models you know. And, no, it's not a model from DeepSeek, OpenAI, Google, X, or Meta.
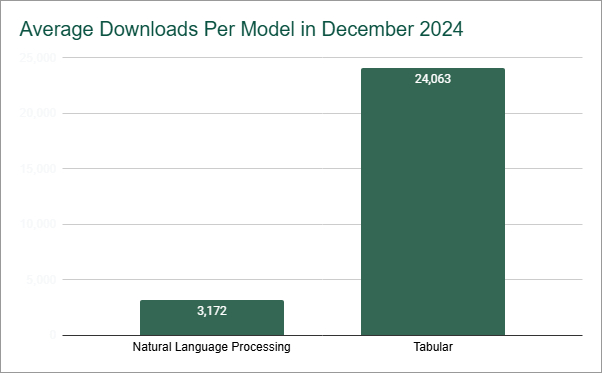
Our first article about AI discussed how recent AI events from China challenge the mainstream understanding of AI. Another prevalent misconception, especially outside of the technology space, is that generative AI encompasses the entire AI category of models, and that is not the case. For instance, one of the most popular types of open-source AI models gets eight times as many downloads as the average open-source natural language processing ("NLP") model. Interestingly, most people have never heard of it. It doesn't appear on hot AI trends lists. In fact, there are over 750 NLP models for every one of these types of models.
But if you have massive data sets (millions of entries), this type of model is likely an indispensable tool for your team. Let's dig into Tabular Machine Learning.
What are Tabular Machine Learning Models?
It's not just about what to do with the data, it's about detecting patterns from millions of rows of data.
During the past ten years, enterprises have commonly complained about making sense of the volume of data they have collected. This data could include web analytics, machine logs, and transaction histories. It's not just about what to do with the data, it's about detecting patterns from millions of rows of data. Predictive maintenance is a good example, which helps with the sustainability of machines or other building systems. Humans are unlikely to be able to process data sets of this size easily. This is where Tabular data models add value.
Enterprise use cases for Tabular Models
Tabular models are horizontal in nature and are designed to work well with structured data sets of any kind. This level of versatility is a big benefit since Tabular Models can be employed for many use cases, including:
Predictive Maintenance
Customer Segmentation
Customer value and churn forecasting
Fraud Detection
Drug discovery and trail reporting
Small Tabular Models are very powerful
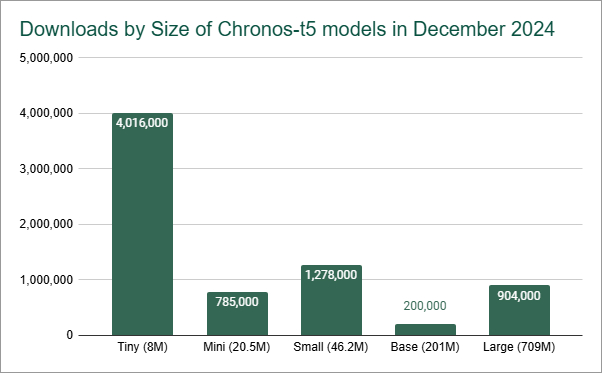
In the case of Tabular Models, Chronos T5 Small and T5 Tiny were the two most popular versions as of December 2024, according to Liftr Insights data.
As we mentioned in last post about DeepSeek, AI models do not have to be big to be powerful. Like large language models, Tabular models come in different sizes depending on the features and performance of the task. In the case of Tabular Models, Chronos T5 Small and T5 Tiny, both products of Amazon, were the two most popular versions as of December 2024, according to Liftr Insights data. These models are great because they can process tens of thousands of rows running on a laptop. This is useful for many enterprise scenarios or as a testing and training environment for larger data sets. Offloading testing and training work to local machines without GPUs is a common way to reduce the impact of more expensive and energy-consuming cloud or server instances.
2 Generations of Chronos are the dominant Tabular model
The older generation T5 models are among the 500 most popular models as measured by downloads.
Liftr Insights data show two distinct groups of Chronos models. The older generation T5 models are among the 500 most popular models as measured by downloads. These models have a very rich feature set ideal for data scientists. The newer Bolt models may not be quite as popular (yet) but are designed with ease of use in mind, including support for non-contextual prompting and high-speed analysis common with business analysts and power users.
Chronos models are sneaky popular
Liftr's reports show that the Natural Language Processing category is the most popular, with more than 300,000 distinct models.
One historical selection metric many enterprises use is the aggregate number of downloads an open-source artifact may have. The theory behind this is that downloads are a proxy for real-world adoption and/or enterprise readiness. However, finding that number is more difficult in the world of AI versus an open-source web server or database. Models are often made available across many products, established cloud platforms, and new platforms like Hugging Face, and some of those platforms do not readily share downloads or usage metrics. It prompts a question: are downloads still an appropriate measure? (It's one of the reasons Liftr Insights data include other types of metrics.)
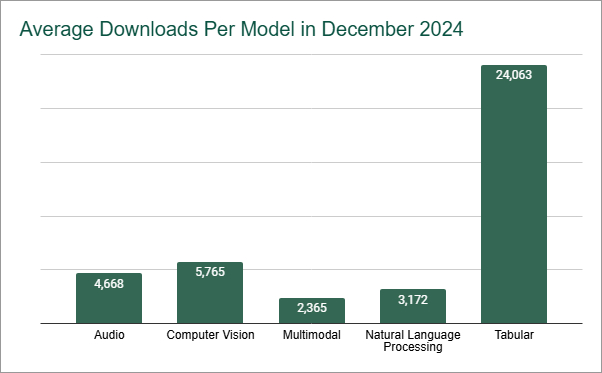
Tabular models have only 1.0% of the total NLP downloads, but the average number of downloads per model is over 24,000.
We believe models should be compared to other models within in the same category. For example, Liftr's reports show that the Natural Language Processing category is the most popular, with more than 300,000 distinct models. However, the average number of downloads per model is about 3,200. Tabular models have only 1.0% of the total NLP downloads, but the average number of downloads per model is over 24,000. In fact, the Tabular model category has the highest number of downloads per model across any category. This does not suggest Tabular models are better than NLP. But, if you are looking at Tabular models, the threshold for what's popular or what a "good" number of downloads should be, it's going to be higher than 24,000.
Liftr Insights: Going beyond the cloud and into AI
At Liftr Insights, we aim to help enterprises and investors make data-driven decisions based on reliable and well-curated market analytics. Liftr has more than half a decade of experience and curated data from the top nine cloud providers. These insights have helped enterprises and investors decide which capabilities fit them, including regional availability, price/performance, and the availability of the right instances.
When considering your AI strategy, it's better to understand the data and the trends than just trusting what the mass market and well-monied vendors tell you. In this blog series, we will discuss some of what we learned with our new AI data set. In our next post, we will discuss how single-contributor AI projects like timm can have an outsized impact in a market dominated by giants.
To stay on top of news about AI like the above (including the next in the series of articles about AI), subscribe to the newsletter today.