
🚨 Not All Open Source Is Created Equal 🌐
Would you like to be featured in our newsletter🔥 and get noticed, QUICKLY 🚀? Simply reply to this email or send an email to editor@aibuzz.news, and we can take it from there.



Hugging Face is the leading repository for open source AI models and datasets. As of April 2025, there were 68 different open source licenses across the over 1.3 million active downloadable models on Hugging Face. In this post we will distill noteworthy differences between the licenses, highlight the key trends of these AI licenses, and evaluate the resulting implications.
Why 68 different licenses?
To the uninitiated it may be a surprise that there are so many different open source licenses since open source is commonly portrayed as one ecosystem. However, licensing of open source packages is a serious decision for creators and 3 key factors drive it:
Monetization Strategy – How will the owner use this to drive a monetary result?
Recruitment of Contributors – Does the owner want others to add and share code to the package?
Intent to scale users (i.e., adoption) – How broadly does the owner want to distribute the package to a given audience?
As of April 2025, there were 68 different open source licenses across the over 1.3 million active downloadable models on Hugging Face.
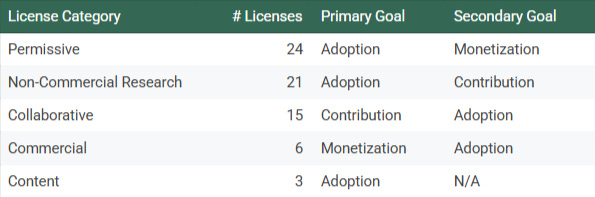
Upon consideration of these factors we can see that there are 5 distinct license categories:
Liftr conducted an analysis of the open source licenses between October 2024 and February 2025 and here are some of the key findings.
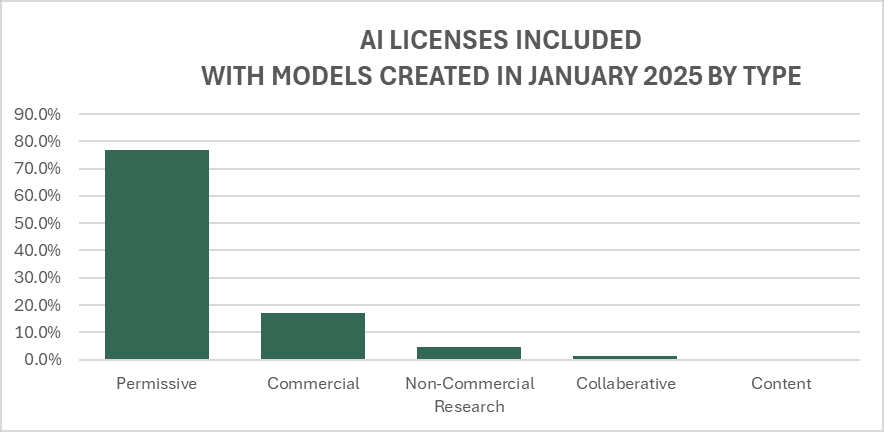
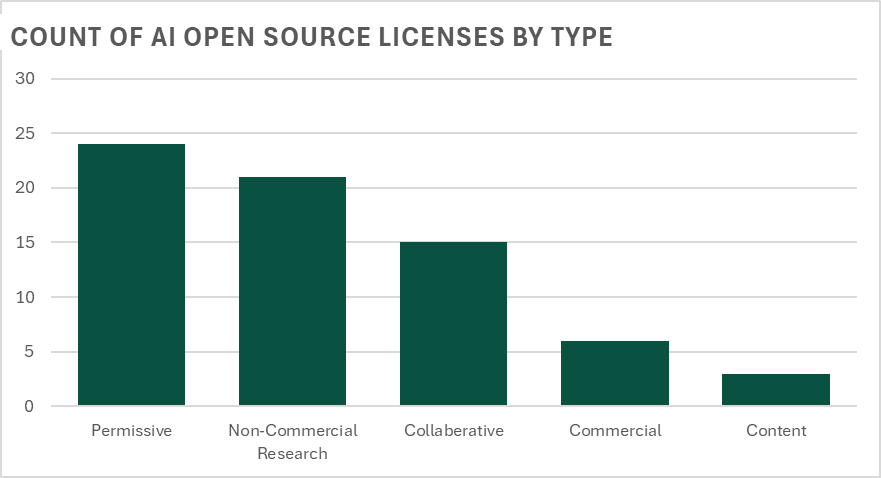
Permissive licenses are the most prevalent type of license and have grown the fastest over the period. This makes sense since the primary objective is to get people downloading and using the package. Since the secondary goal is monetization, there will typically be marketing support from the package creator(s). Examples of permissive licenses include Apache and MIT.
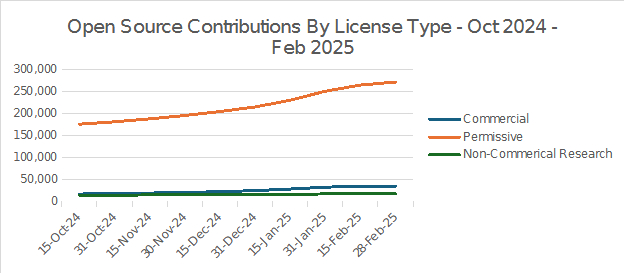
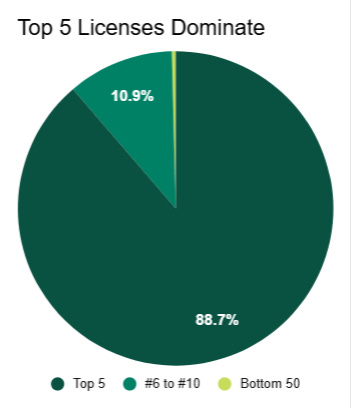
The top 5 licenses account for the gross majority of new package contributions at 88.7%, and they are a combination of Permissive and Commercial licenses. Again, since Permissive and Commercial licenses are packages with monetization implications there will be more marketing support. These permissive licenses also favor reuse by partners, so there is a higher likelihood of cross-pollination and integration of the code. The Commercial licenses in this majority include Llama, from Meta, and Gemma, from Google.
Non-Commercial Research licenses prioritize easy sharing of AI data and models between institutions and in many cases these licenses specifically forbid monetization.
Research is still a major influencer on open source strategy. It’s important to remember that the originators of open source did not prioritize monetization. While success stories from open source, including Red Hat Enterprise Linux and the Eclipse development toolset, are monetization plays, there is still a healthy and vibrant academic and scientific open source ecosystem. For example, there are 21 different open source licenses categorized as Non-Commercial Research. These types of licenses prioritize easy sharing of AI data and models between institutions and in many cases these licenses specifically forbid monetization. Models in this category include OpenRail and Big Science Bloom.
Open source remains a major driver of innovation and adoption in the AI era. However, the AI era and other previous open-source eras do share some things in common. For example, permissive licensing has been a consistent trend since the early days of open source. We are also seeing a return of other types of licenses to facilitate research in not only science but in other areas such as responsible AI. We will continue to monitor these events as AI gets broader adoption to see how the market and ecosystems develop.
To stay up to date on AI insights like the above and other related news, subscribe to the Liftr Insights newsletter.